Here is a summary of a second talk, which was held in front of a smaller, more specialized audience (Artificial Intelligence lab seminar, Edinburgh University).
The title of the talk was
Dark Side of the semantic web
Dark side in the title doesn't refer to a negative force but more to the hidden face of the moon. The fact that when people talk about the semantic web, the predominant concept that comes across is semantic... while the web part is important as well.
A notion Prof. Hendler used very often during his talks, using different
allegories is the one that power comes from putting together a variety of islands of knowledge that pre-existed, linking them together.
This is really what the semantic web is about. Data integration and Concept linking. To quote Prof Hendler: "Linking is power". Resources power by exploiting links to web resources, data resources, each other, web 2.0 like annotations on web resources, or annotations in official resources.
An interesting characteristic of semantic web technologies compared to usual technologies is that as in many other domains, both a high end and a low end coexist (high end = big corporation with huge amounts of data to manipulate and huge budgets to buy or fund the design of specialized tools; low end = hackers, hobbyists, small or even one person teams). However, here it seems that commercial success opportunities (making money) is more apparent in the low end than in the high end. What we see mostly is commercialisation coming from ajax, 3 tiers web architecture, etc. Commercial success doesn't come that much from the ability to design a tool that will implement complex processes to manipulate huge amounts of data. It rather comes from using a bit of help from knowledge to make an application more intelligent and more interesting to the end user.
------------------------------------------------------------------------------
Then followed a few slides with a number of acronyms
-
RDF,
OWL (ontology web language),
SPARQL (query language for RDF) [TBD: explain what these technologies are about]
-
RIF: Rules Interchange Format
-
(Open)Cyc : world's largest and most complete general knowledge base and commonsense reasoning engine.
-
SKOS (Simple Knowledge Organization System)
-
LSID (Life Sciences Identifier)
-
MMORPG (massive multiplayer online role-playing game)
Most of these appear in some form in the layer cake that Berners-Lee is used to show in his presentations

(this is a kind of old version, the guy showed an expanded version where in place of ontology vocabulary, you had SPARQK, OWL, RDF)
The version most like the one that was presented is this:
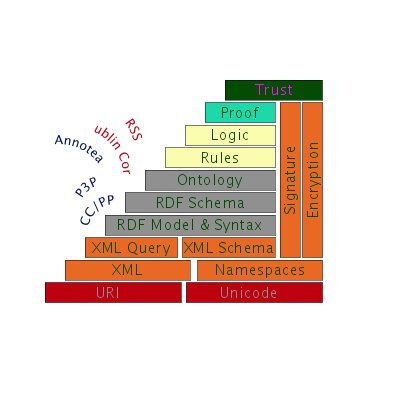
Basically, that graph is supposed to capture all the different layers that the semantic web is made of.
------------------------------------------------------------------------------
An excellent point Prof. Hendler made was that most of these technologies were fairly complex and required kind of big time investment to get to master them and understand what was possible or not to do with them. Even if a good collection of tools starts to exist, it still remains that access to these technologies is not a piece of cake.
To quote him. "If you believe in a vision, then you should make it easy for developers to follow that vision."
Ontologies can be used to capture any knowledge expressed in a semi-structured way.
A new interesting trend is therefore to propose subsets of these RDF/OWL technologies. Initially, it was thought that persons would request more expressivity for these markup languages. The trend now is to rather request for more specific, limited expressivity... to use only the little bit of expressivity that helps you a lot and leave on the side the more extended expressivity that you only require very occasionally.
He mentioned various initiatives in that direction
- GRDDL embedding RDF into traditional content (alike microformats, I assume) -- apparently
a way of extracting RDF from XML docs (using XSLT). There is some
w3 info on this.
- OWL mini (or OWL Fast, or OWL Prime, or OWLET, or whatever it might end up being called). That's kind of new and you don't really find much more than
mailing list posts on the topic.
- RDF++. Again, something that appears very much under development. Some
blog posts and
internal presentations
------------------------------------------------------------------------------
A few more points:
1. According to James Hendler, the data sources that are being queried after some code is being executed have started to change from data stored in a relational database to data stored in a
RDF triple store. In short, "RDFStore implements a generic hashed data storage that allows to serialise RDF models, resources, properties and property values either to disk or in-memory data structures."
2. What's so special about RDF/OWL?
A. To start with, they don't require a priori fully structured representation of the knowledge like relational database. They are designed to cope with semi-structured types of knowledge.
B. RDF+OWL are designed to live in an open and distributed environment.
C. If you take OWL, for instance, it is grounded into URI (Uniform Resource Identifier). This means that anywhere within your knowledge tree, you put a URI as content of a node. Rather than give a definition of a term or clone the definition form elsewhere like you would be forced to do in a relational database, you can simply refer to some knowledge that is held elsewhere (and eventually kept up to date on that other site). The big distinction then to make is between the URL that corresponds to the usual web page model which can link to a web page like the one of the Guardian (a newspaper in the UK) where the information is susceptible to change everyday and a URI to be used in a knowledge tree. In the second context, the URI doesn't let you retrieve information content per se but information about where that information content is to be found. An important implication of this is of course that the URI for this second type of resource (pointer to the information content) has to remain persistent for it to be useful to link to it.
D. Ontologies allow for web-like relationships between data, which is not easily done in a typical relational database. This corresponds to a point he made 3 time during the talk. The general idea being that links on the web have some paralell with links int he real world. He made a connection with this:
Connected Services Framework 3.0 Developers Guide.
3. The current model of the web is one where information is being pulled. Though Ajax can make the Pull happen a lot quicker and give an illusion of push technology, it still remains a Pull model. Agency would have for contribution to act as pushing agents (probably of more specific interest for mobile web technologies).
------------------------------------------------------------------------------
Further readings
-
Spinning the Semantic Web (book), with a
Review
-
Three Theses of Representation in the Semantic Web
-
Agents and the Semantic Web by Ky Van Ha (2005)
-
Access Control on RDF Triple Stores from a Semantic Wiki Perspective (pdf) by Horrocks, I., & Patel-Schneider, P.F. (2003)
Further Links
-
Swoogle - Semantic Web Search. Swoogle is a crawler-based indexing and retrieval system for the Semantic Web. That is, it indexes RDF and OWL documents, rather than plain HTML documents.
-
ebiquity - Building intelligent systems in open, heterogeneous, dynamic, distributed environments. Check out the blog, in particular.
-
Ontology Resources on the RevEd wiki